
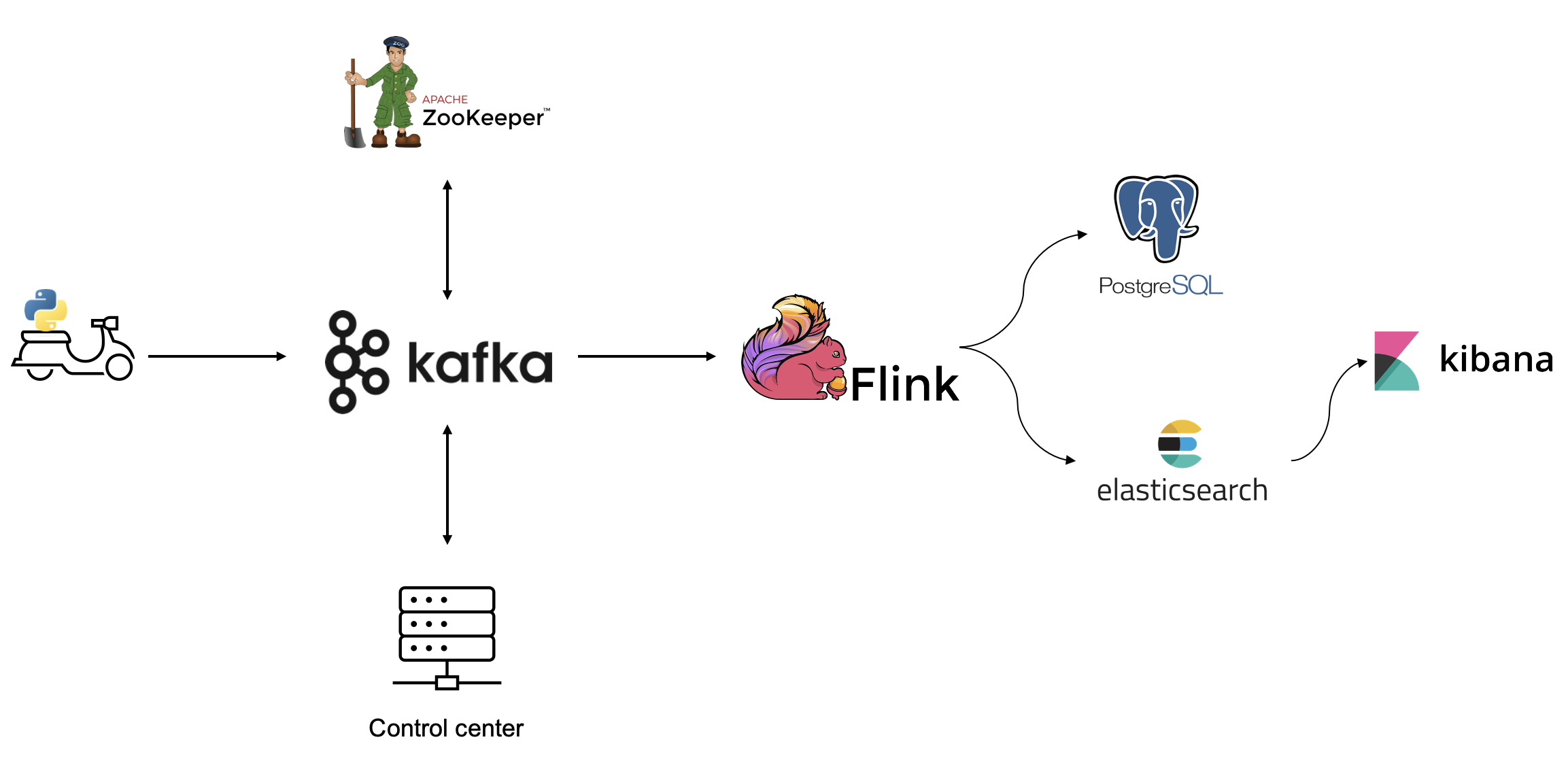
Flink Job을 사용한 Kafka 메시지 스트리밍
데이터 수집에서 파이썬으로 데이터를 생성하고 kafka에 메시지를 publish 했다. 이제 flink로 kafka에서 메시지를 소비하고 변환 및 집계 연산을 수행해야 한다.
일단 kafka에서 파이썬으로 생성한 데이터를 그대로 잘 가져오는지 확인해본다.
환경 구축에서 archetype을 flink-quickstart-java로 지정했다면 프로젝트 파일에 아래처럼 스켈레톤 코드가 작성되어 있다.
Flink 공식 문서에 kafka connector를 사용해 데이터를 읽는 방법이 자세하게 쓰여있다.
At-least-once, At-most-once, Exactly-once 3가지의 이벤트 처리 보장 중 가장 신뢰할 수 있는 exactly-once 방법으로 kafka topic으로부터 데이터를 읽을 수 있다고 설명되어 있다.
공식 문서에 쓰여있는 대로 버전을 맞추어 dependency를 추가한다.
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka</artifactId>
<version>3.1.0-1.18</version>
</dependency>예시를 보면 어떻게 kafka로부터 데이터를 읽는지 바로 알 수 있다. 예시는 String 타입으로 역직렬화한다. 따라서 직접 Delivery 객체를 정의하고 kafka에서 읽어온 데이터를 해당 객체로 역직렬화 하도록 수정해야 한다.
// 공식 문서 예시
KafkaSource<String> source = KafkaSource.<String>builder()
.setBootstrapServers(brokers)
.setTopics("input-topic")
.setGroupId("my-group")
.setStartingOffsets(OffsetsInitializer.earliest())
.setValueOnlyDeserializer(new SimpleStringSchema())
.build();
env.fromSource(source, WatermarkStrategy.noWatermarks(), "Kafka Source");Delivery Class 정의
파이썬에서 json 형식으로 kafka에 메시지를 publish 했으므로 key가 그대로 클래스 멤버 변수가 된다.
package dto;
import lombok.Getter;
import java.sql.Timestamp;
@Getter
public class Delivery {
private String deliveryId;
private Timestamp deliveryDate;
private String userId;
private String foodCategory;
private double foodPrice;
private String paymentMethod;
private double deliveryDistance;
private String deliveryDestination;
private double destinationLat;
private double destinationLon;
private int deliveryCharge;
}평소처럼 lombok의 @Data 어노테이션을 사용할까 했다. 그런데 많은 사람들이 무분별한 setter 사용 등의 이유로 @Data를 지양해야 한다고 말한다. 역시 편하다고 다 좋은게 아니다.... 검색을 많이 해봤는데 김영한님은 이렇게 답변하셨다. 좋은 방법은 무엇인지 더 공부하고 찾아봐야 할 것 같다.

역직렬화
공식 문서 예시와는 다르게 kafka로부터 데이터를 읽고 Delivery 객체로 역직렬화를 수행해야 한다.
.setValueOnlyDeserializer(new SimpleStringSchema())이 부분이다. 수정을 위해 setValueOnlyDeserializer, SimpleStringSchema가 무엇을 하는지 알아야 한다.
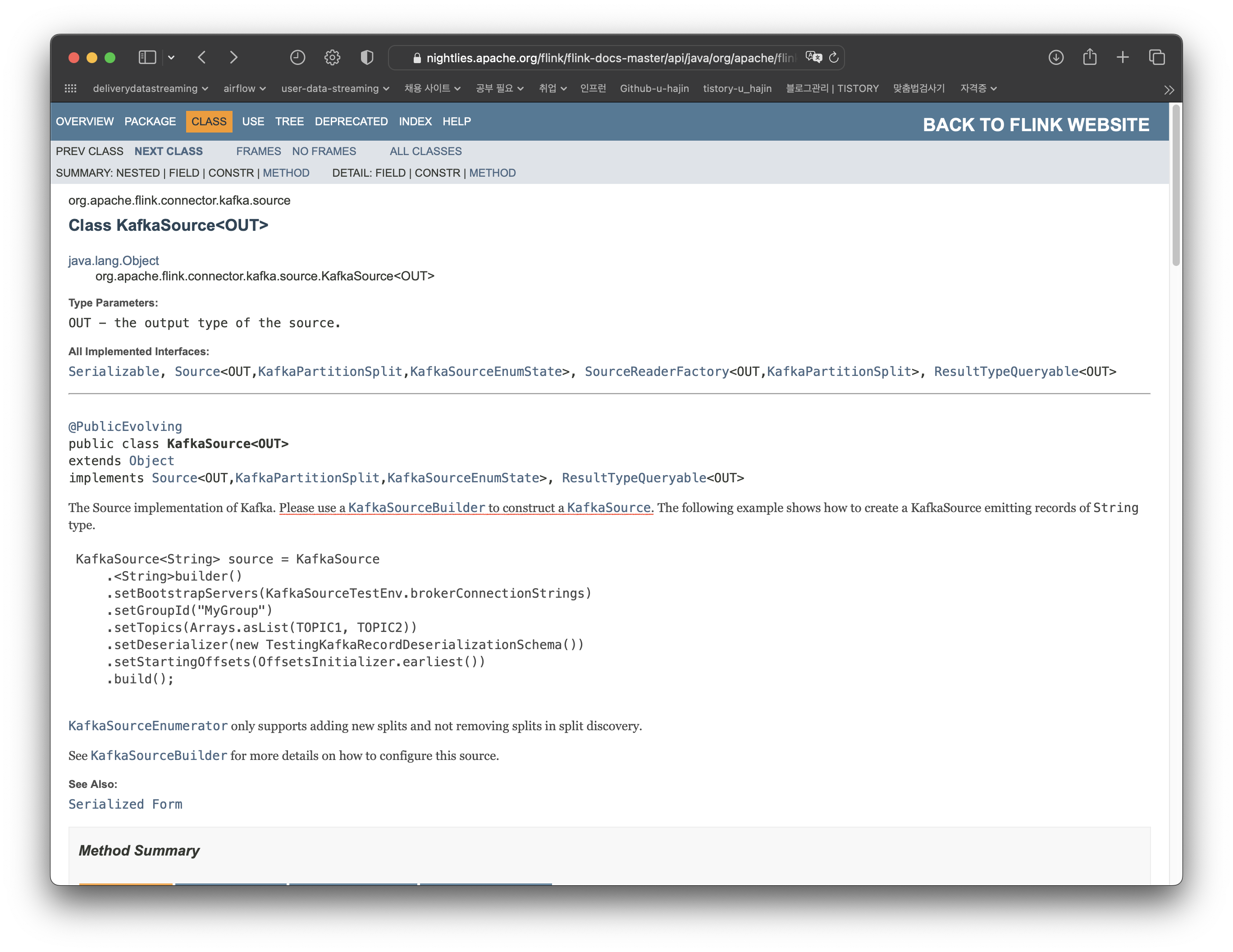
KafkaSource를 위해 KafkaSourceBuilder를 사용하라고 한다. 그럼 KafkaSourceBuilder에 setValueOnlyDeserializer 함수 설명이 있을 것이다.
KafkaSourceBuilder 설명에 역직렬화를 위한 함수가 2개가 있다.
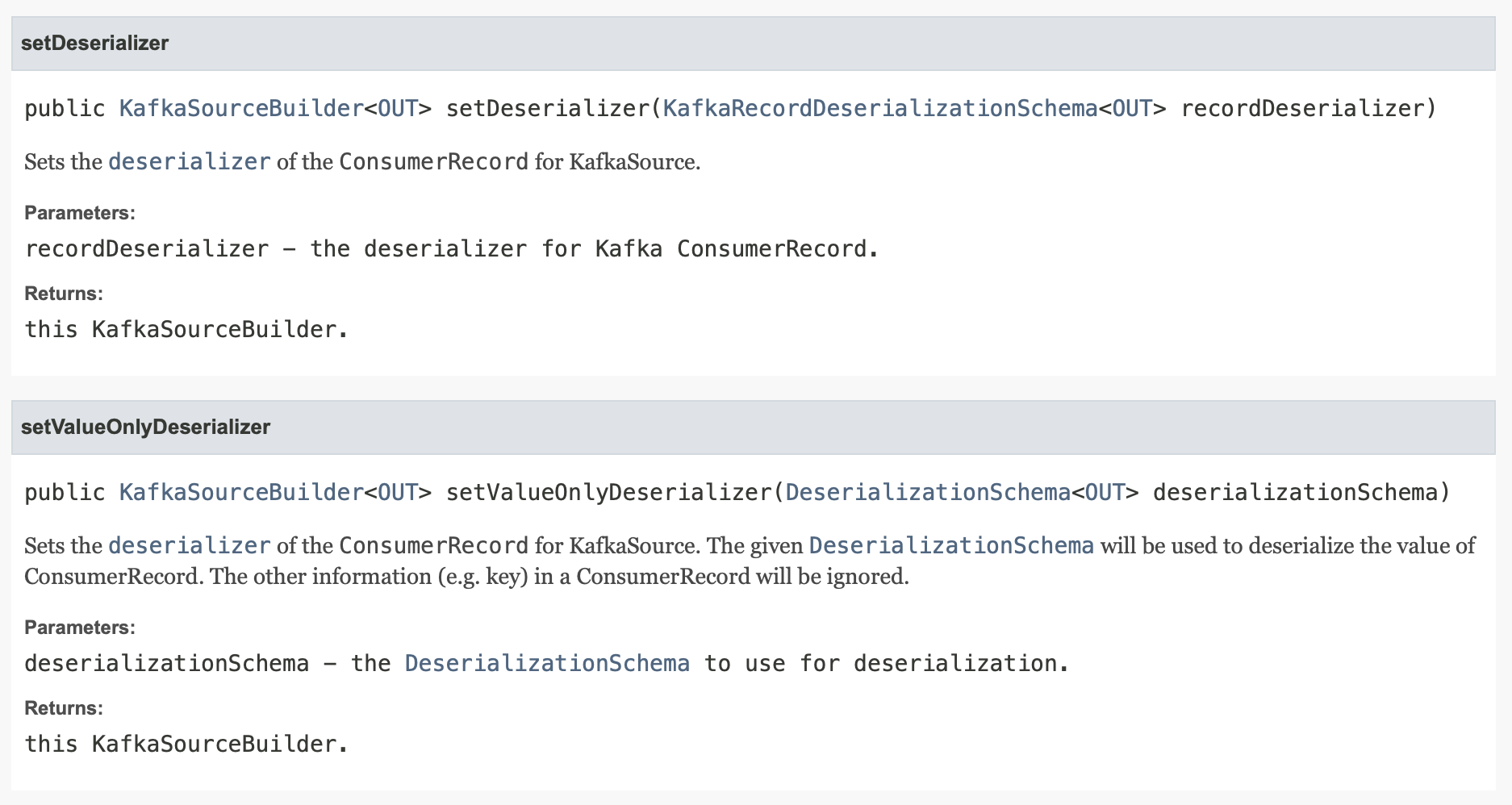
두 함수 모두 사용할 수 있지만 setDeserializer의 경우 kafka 메시지의 key와 값에 대해 별도의 deserializer 설정, setValueOnlyDeserializer의 경우 메시지의 값에 대한 deserializer만을 설정할 때 쓰인다. 키를 사용하지 않기 때문에 setValueOnlyDeserializer를 사용하면 될 것 같다.
그럼 이제 DeserializationSchema가 무엇인지 봐야한다... 처음 사용해보는 거라 시간이 오래 걸린다.
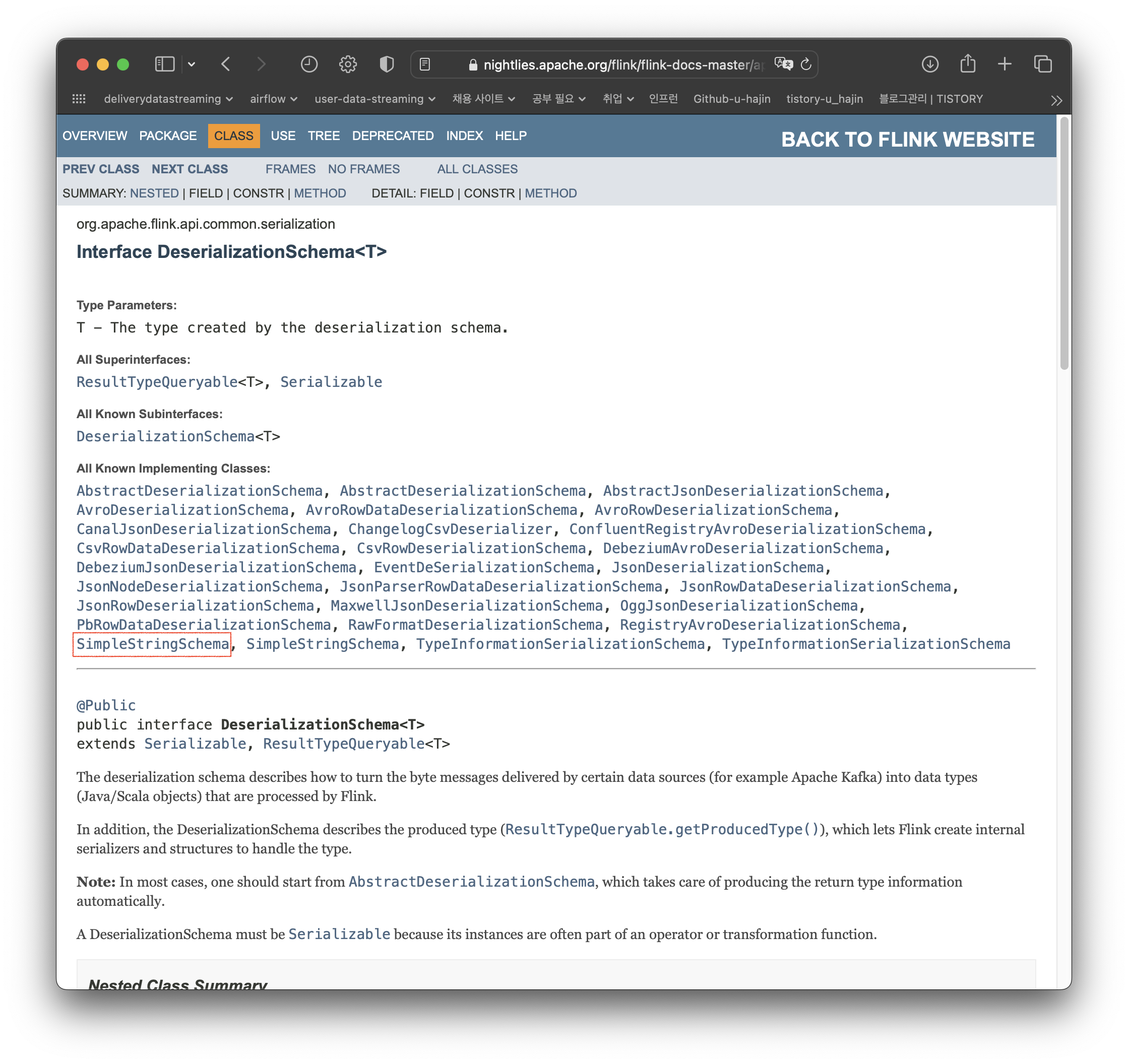
아까 봤던 SimpleStringSchema도 나와있다. DeserializationSchema 인터페이스를 구현하면 될 것 같다.
그럼 이제 json을 java object로 변환하는 방법을 알아야 한다.
// 출처: https://ioflood.com/blog/json-to-java-object/
ObjectMapper objectMapper = new ObjectMapper();
String jsonString = "{"name": "John Doe", "email": "john.doe@example.com"}";
User user = objectMapper.readValue(jsonString, User.class);Jackson의 objectMapper를 사용하면 쉽게 변환할 수 있다.
private final ObjectMapper objectMapper = new ObjectMapper();
@Override
public Delivery deserialize(byte[] bytes) throws IOException {
return objectMapper.readValue(bytes, Delivery.class);
}
@Override
public TypeInformation<Delivery> getProducedType() {
return TypeInformation.of(Delivery.class);
}주요 메서드만 가져왔다. deserialize 메서드에서 objectMapper.readValue로 bytes를 입력하고 Delivery 객체를 반환하도록 한다.
Flink Job 실행 및 데이터 확인
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.enableCheckpointing(30000);
String topic = "delivery_information";
KafkaSource<Delivery> source = KafkaSource
.<Delivery>builder()
.setBootstrapServers("localhost:9092")
.setTopics(topic)
.setGroupId("flink-group")
.setStartingOffsets(OffsetsInitializer.earliest())
.setValueOnlyDeserializer(new JsonValueDeserializationSchema())
.build();
DataStream<Delivery> deliveryStream = env.fromSource(source, WatermarkStrategy.noWatermarks(), "Kafka source");
deliveryStream.print();Watermark는 이벤트 시간이 얼마나 진행되었는지를 나타내는 시간 기반의 타임스탬프이고 이벤트 시간에 기반한 데이터 스트림 처리에서 지연을 관리할 때 사용되는 개념이다.지금은 필요하지 않으므로 watermark를 생성하지 않는 방법을 택했다.
이제 flink job을 실행시켜본다.


Job has been submitted with JobID~ 가 출력되면 아래처럼 UI에서 확인할 수 있다.
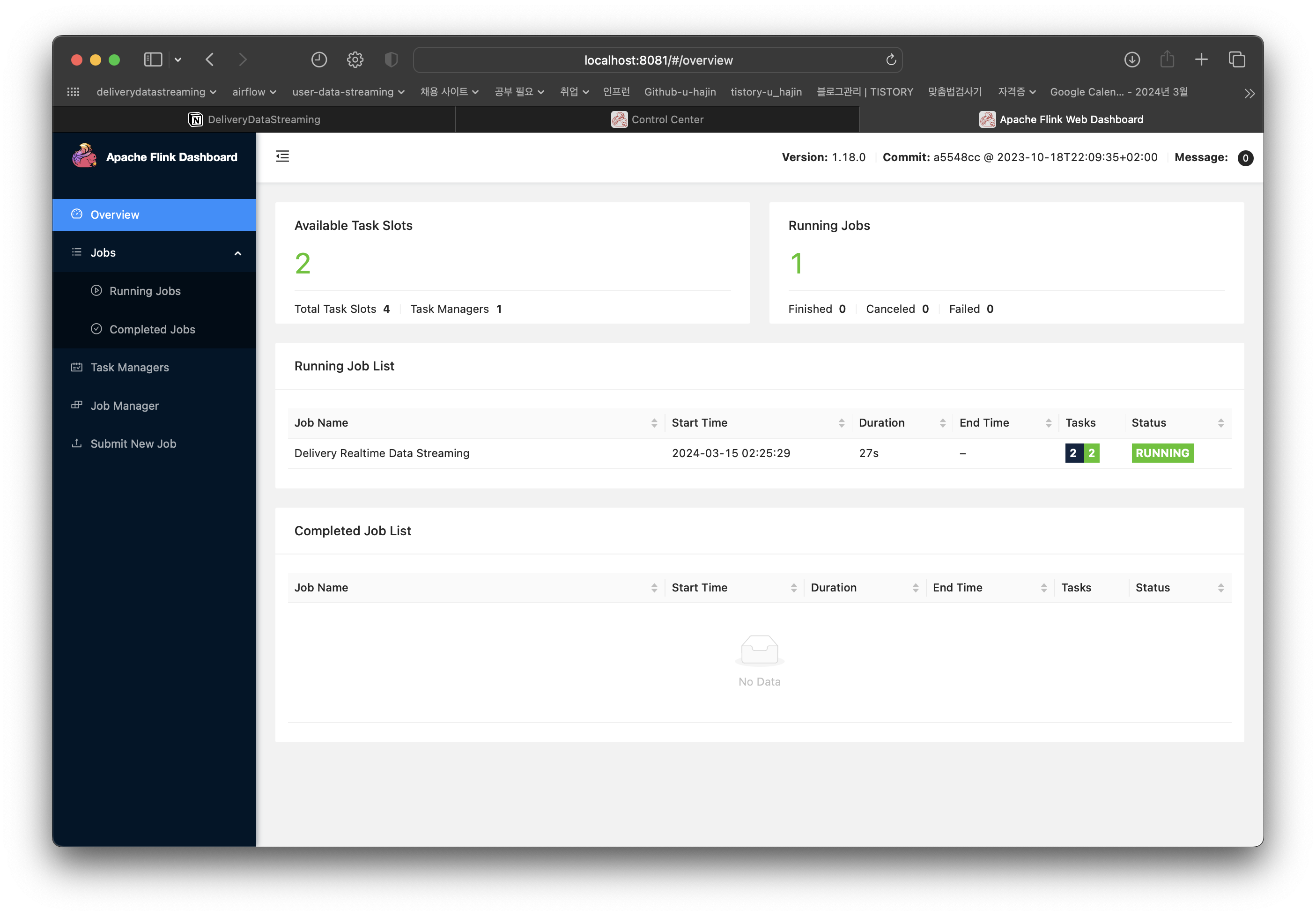
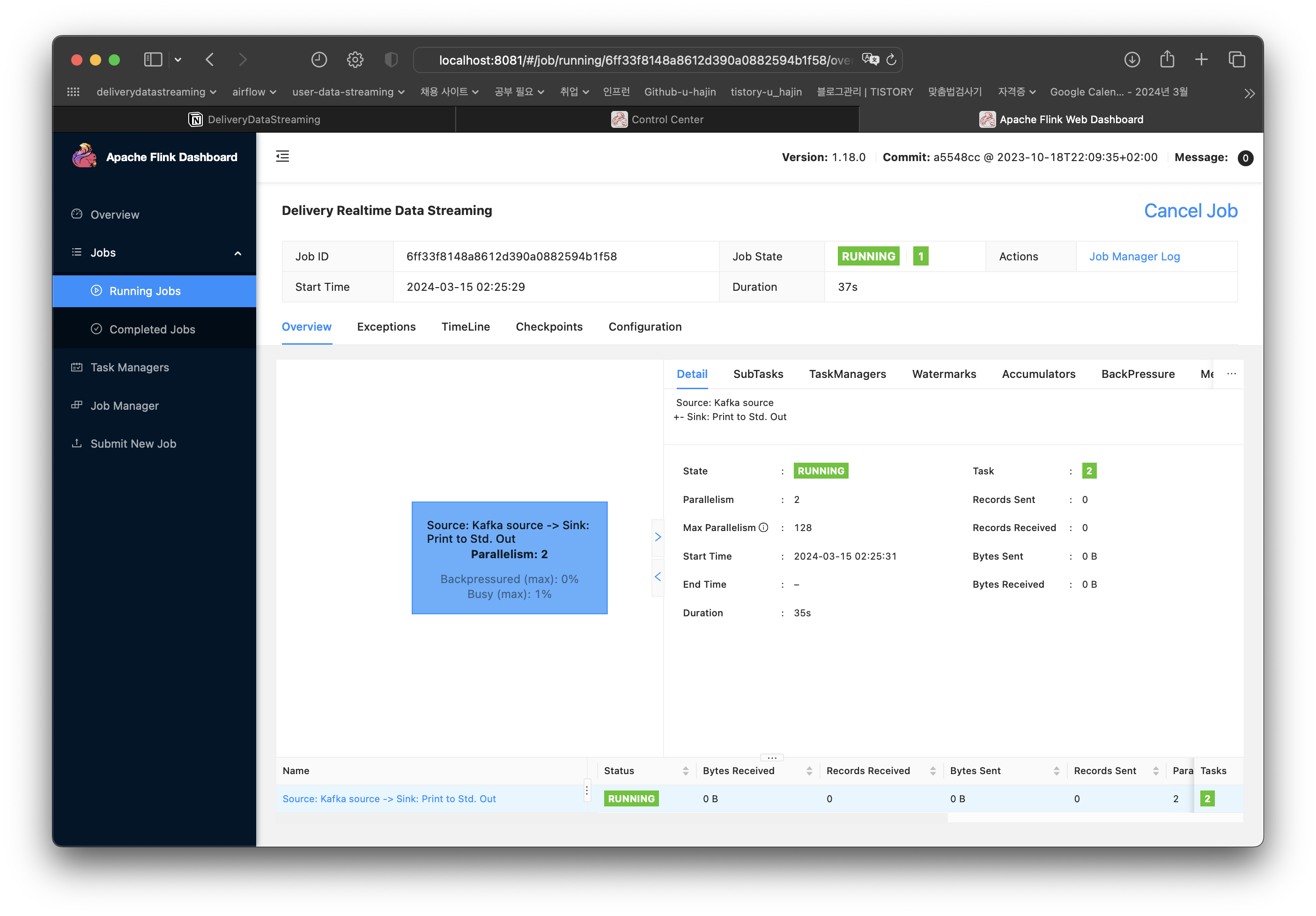
DataStream이 출력되도록 했으니 로그를 확인하면 데이터를 잘 읽어왔는지 확인할 수 있다.
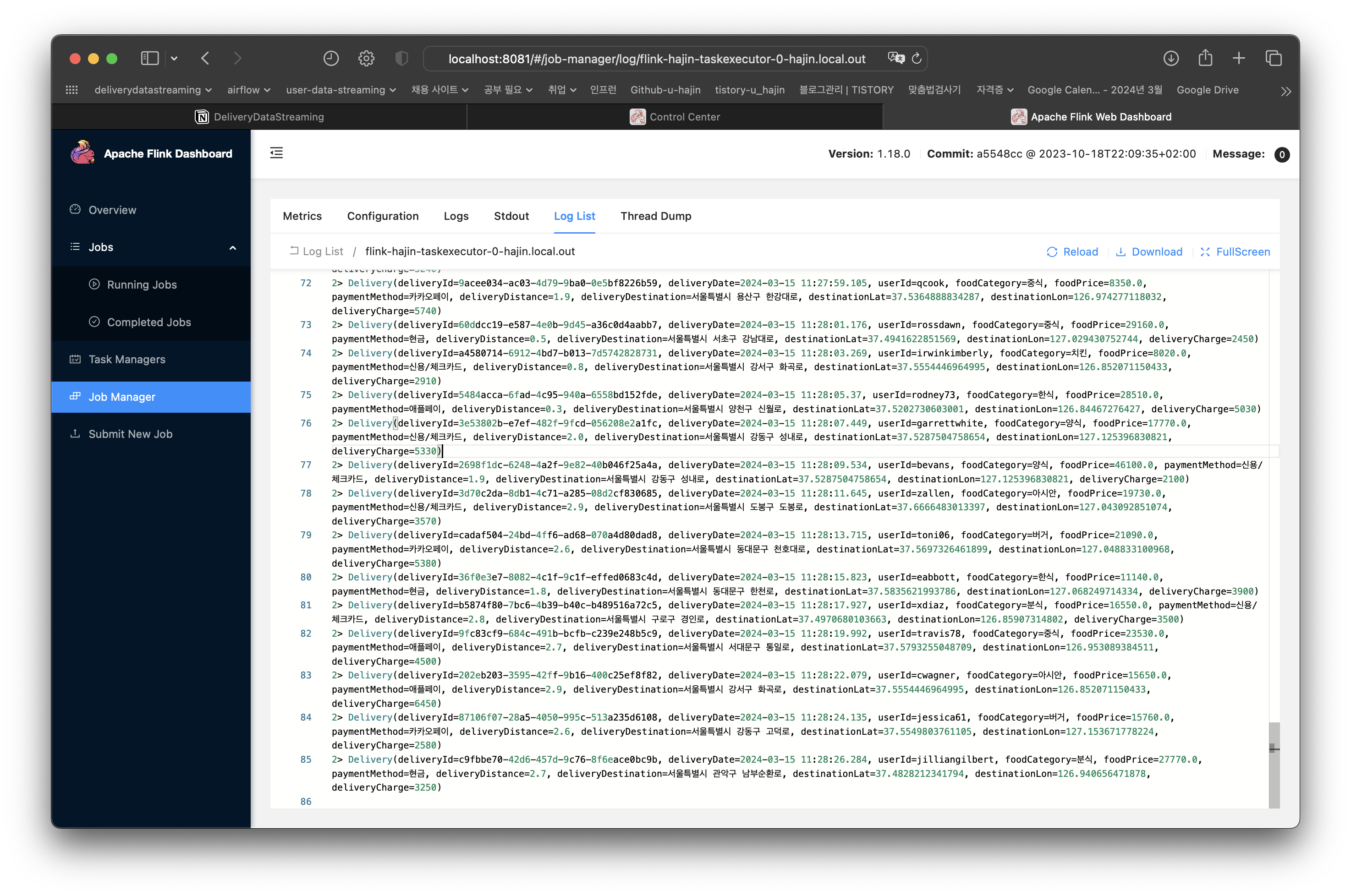
파이썬에서 생성한 데이터 그대로 잘 읽어온 것을 확인할 수 있다.
Github
GitHub - u-hajin/delivery-data-streaming: 실시간 배달 주문 데이터 처리
실시간 배달 주문 데이터 처리. Contribute to u-hajin/delivery-data-streaming development by creating an account on GitHub.
github.com
'Data > Project' 카테고리의 다른 글
| Project | 실시간 배달 주문 데이터 처리 - Flink Map, KeyBy, Reduce를 이용한 데이터 변환, 집계 처리 (2) | 2024.05.03 |
|---|---|
| Project | 실시간 배달 주문 데이터 처리 - PostgreSQL Table 생성 및 데이터 삽입 (0) | 2024.05.03 |
| Project | 실시간 배달 주문 데이터 처리 - 데이터 수집 (2) | 2024.03.18 |
| Project | 실시간 배달 주문 데이터 처리 - 환경 구축 (2) | 2024.03.18 |
| Project | 실시간 배달 주문 데이터 처리 - 시스템 구조 및 설명 (0) | 2024.03.18 |