
데이터 구조
Json 형식으로 kafka에 메시지를 publish한다.
| key | value |
| deliveryId | uuid |
| deliveryDate | 배달 주문 날짜 |
| userId | 배달 주문 고객 id |
| foodCategory | 음식 카테고리 |
| foodPrice | 음식 총 가격 |
| paymentMethod | 결제 방식 |
| deliveryDistance | 배달 거리 |
| deliveryDestination | 배달 목적지 |
| destinationLat | 배달 목적지의 위도 |
| destinationLon | 배달 목적지의 경도 |
| deliveryCharge | 배달 요금 |
배달 목적지의 위도, 경도를 데이터에 포함하는 이유는 elasticsearch의 지도를 활용하기 위해서다. 배달 목적지에 따른 주문 빈도수를 지도로 한번에 나타내면 좋을 것 같아 위도, 경도를 저장하기로 했다.
데이터 생성
faker = Faker()
KST = timezone(timedelta(hours=9))
def generate_delivery_data():
data = {'deliveryId': faker.uuid4(),
'deliveryDate': datetime.now(KST).strftime('%Y-%m-%dT%H:%M:%S.%f%z'),
'userId': faker.simple_profile()['username'],
'foodCategory': random.choice(['한식', '중식', '양식', '일식', '아시안', '치킨', '버거', '분식']),
'foodPrice': round(random.randint(5000, 12000) * random.randint(1, 4), -1),
'paymentMethod': random.choice(['현금', '신용/체크카드', '네이버페이', '카카오페이', '애플페이', '토스페이']),
'deliveryDistance': round(random.uniform(0.2, 3.0), 1),
'deliveryDestination': random.choice(seoul_addresses)}
kakaoApiKey = config['AUTHORIZATION']['KakaoApiKey']
location = get_location(data['deliveryDestination'], kakaoApiKey)['documents'][0]
data['destinationLat'] = location['y']
data['destinationLon'] = location['x']
data['deliveryCharge'] = round(random.randint(1000, 5000) + (data['deliveryDistance'] * 500), -1)
return data- deliveryId : faker 라이브러리를 사용해 uuid 값을 생성한다.
- deliveryDate : 타임존을 한국으로 설정해 현재 시간을 저장한다.
- userId : faker 라이브러리를 사용해 user 아이디를 생성한다.
- foodCategory : 총 8개의 카테고리 중 랜덤으로 하나의 값만 뽑는다.
- foodPrice : 5000~12000 범위를 갖는 랜덤 정수에 랜덤 값(1~4)을 곱해 음식 가격을 생성한다. 일의 자리는 무조건 0으로 지정한다.
- paymentMethod : 총 6개의 방식 중 랜덤으로 하나의 방식만 뽑는다.
- deliveryDistance : 0.2~3.0 범위를 갖는 랜덤 실수를 생성한다.
- deliveryDestination : seoul_addresses 리스트에 125개의 주소가 저장되어 있다. 그 중 하나의 값을 랜덤으로 뽑는다. 주소 형식은 '서울특별시 xx구 xx로'로 통일되어 있다.
- deliveryCharge : 1000~5000 범위를 갖는 랜덤 정수에 배달 거리에 따라 가중치를 주어 값을 생성한다. 일의 자리는 무조건 0으로 지정한다.
위도, 경도 추출
deliveryDestination key에 저장되어 있는 주소를 가지고 위도, 경도를 추출해야 한다. 여러 API 중 kakao에서 제공하는 API가 제일 적당해보였다.
def get_location(address, apiKey):
url = 'https://dapi.kakao.com/v2/local/search/address.json?query=' + address
headers = {'Authorization': apiKey}
location = requests.get(url, headers=headers).json()
return locationdeliveryDestination 문자열을 입력하면 kakao API를 통해 위도, 경도를 추출할 수 있다. 직접 발급받은 kakao api key를 넘겨줘야 한다.
반환받은 location을 출력하면 아래와 같다.
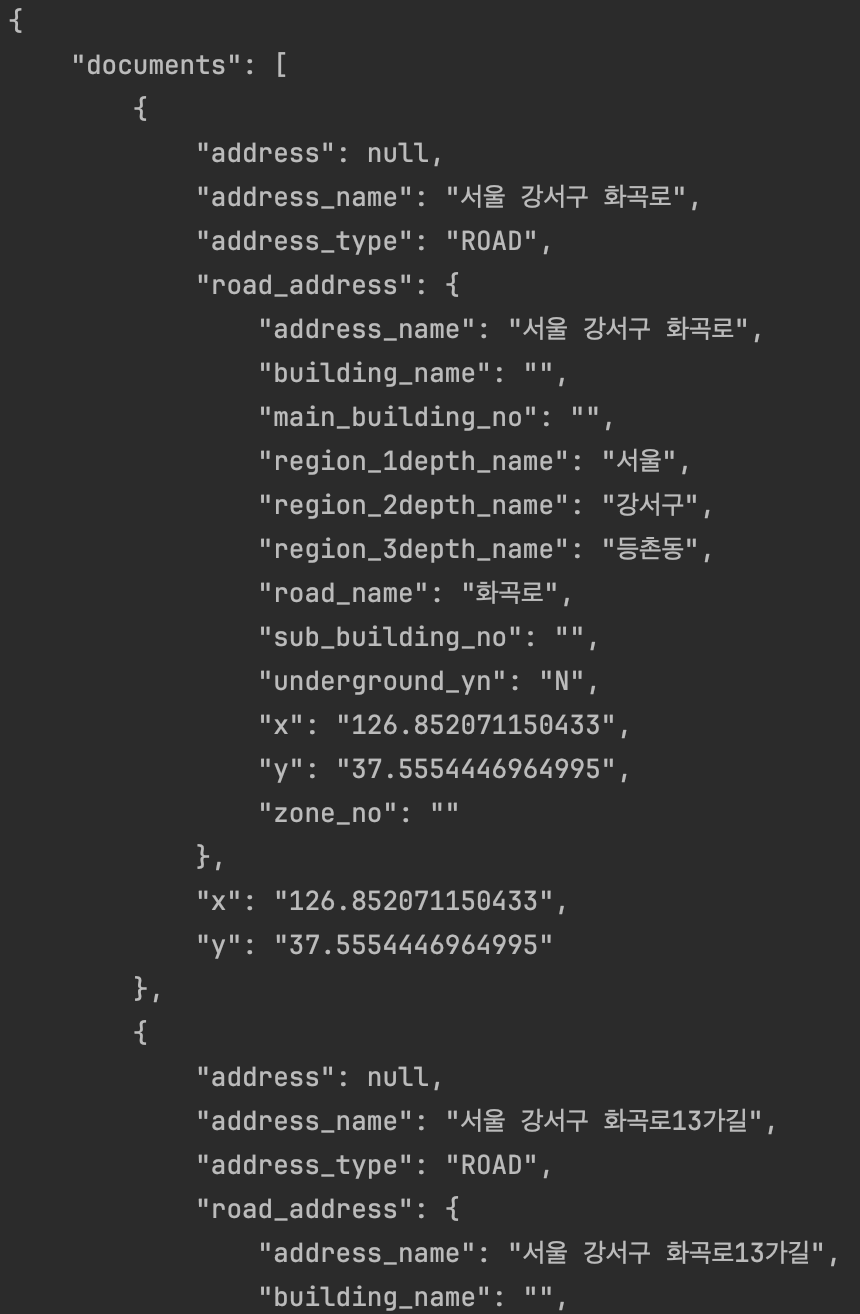
'서울특별시 강서구 화곡로'를 입력하면 얻을 수 있는 값인데 '화곡로'가 포함된 모든 주소에 대한 정보가 포함되어 있다. 이 중 맨 처음 요소의 위도, 경도를 사용하기로 결정했다.
kakaoApiKey = config['AUTHORIZATION']['KakaoApiKey']
location = get_location(data['deliveryDestination'], kakaoApiKey)['documents'][0]
data['destinationLat'] = location['y']
data['destinationLon'] = location['x']
kafka에 publish할 데이터이다.
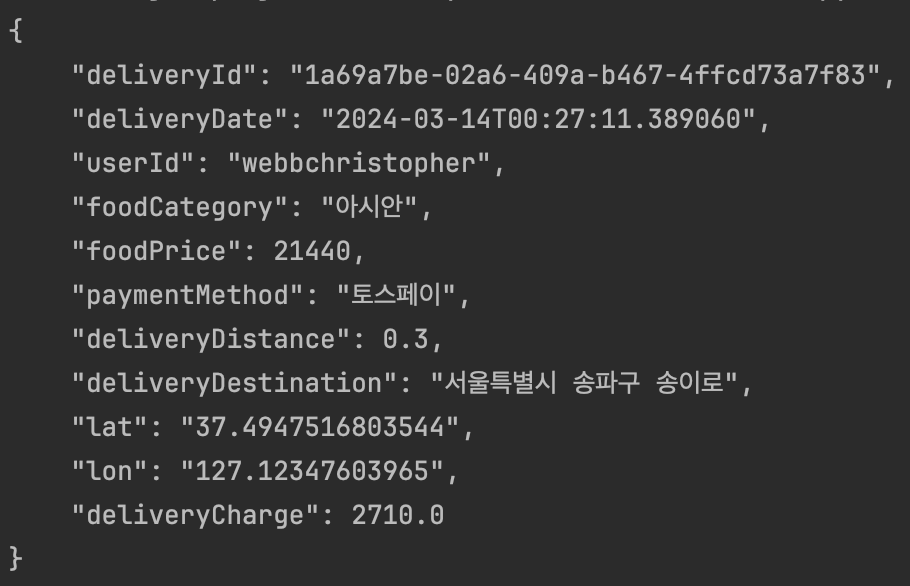
Kafka 메시지 Produce, Publish
confluent_kafka 라이브러리를 사용할 것이다.
먼저 공식 문서를 확인해본다.
confluent_kafka API — confluent-kafka 2.3.0 documentation
Docs » confluent_kafka API View page source confluent_kafka API A reliable, performant and feature-rich Python client for Apache Kafka v0.8 and above. Guides Client API Serialization API Supporting classes ExperimentalThese classes are experimental and ar
docs.confluent.io
producer가 여러개이므로 읽어보고 어떤 클래스를 사용해야 할지 봤다. 메시지를 전송하기 전 직렬화가 필요하면 SerializingProducer를 사용하면 된다고 한다.
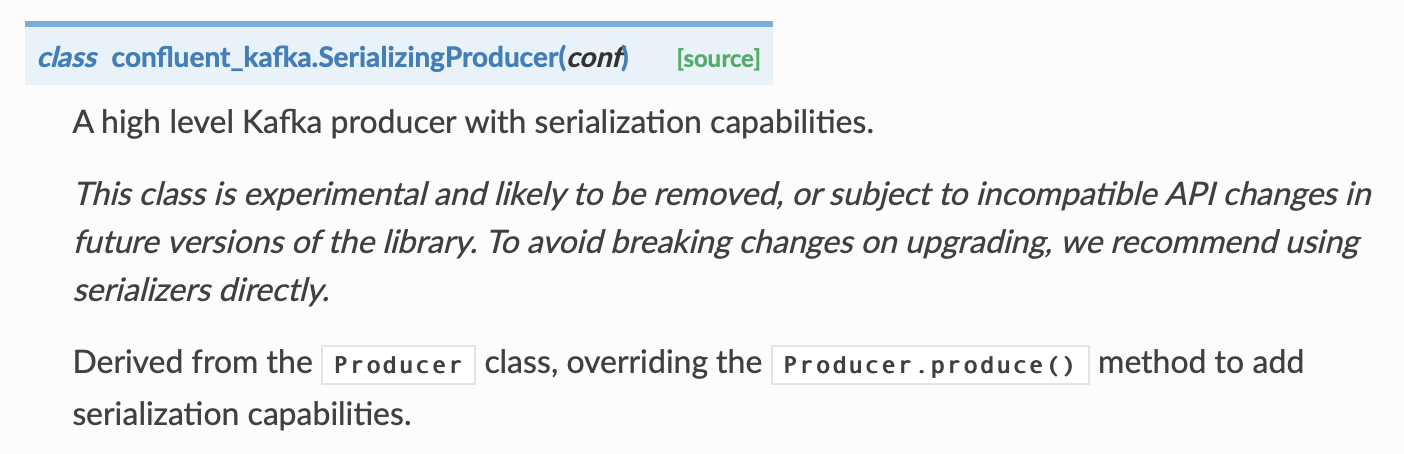
추후 버전에는 포함되지 않거나 달라질 수 있으니 주의해야 한다. Producer 클래스를 상속 받았다고 한다.
그럼 다시 Producer 페이지로 가서 어떻게 producer를 생성해야 하는지 봐야한다.
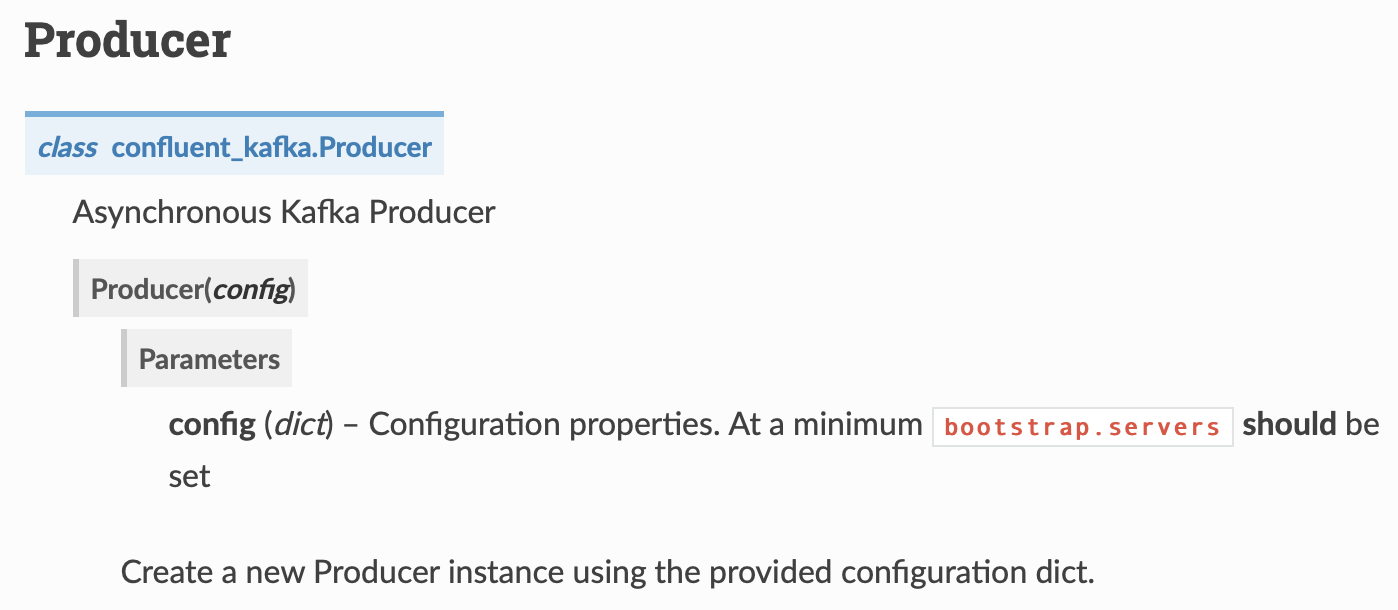
딕셔너리 형태로 bootstrap.servers를 명시하면 된다.
producer = SerializingProducer({
'bootstrap.servers': config['KAFKA']['BootstrapServer']
})
# config['KAFKA']['BootstrapServer'] == 'localhost:9092,localhost:9093'
produce 함수의 파라미터 설명이다. topic, key, value, on_delivery만 넘겨주면 될 것 같다.
on_delivery에는 메시지 전달에 성공하거나 실패했을 때 poll(), flush()로부터 호출될 콜백 함수를 등록한다.
def delivery_report(error, msg):
if error is not None:
print(f'Message delivery failed: {error}')
else:
print(f'Message delivered to {msg.topic()} [{msg.partition()}]')topic = config['KAFKA']['Topic']
def kafka_publish(producer, topic, data):
producer.produce(
topic=topic,
key=data['deliveryId'],
value=json.dumps(data, ensure_ascii=False),
on_delivery=delivery_report
)
producer.poll(0)Topic 이름은 delivery_information이고 key 값은 생성한 데이터의 deliveryId로 지정했다.
produce 함수 호출로 메시지를 publish한다.
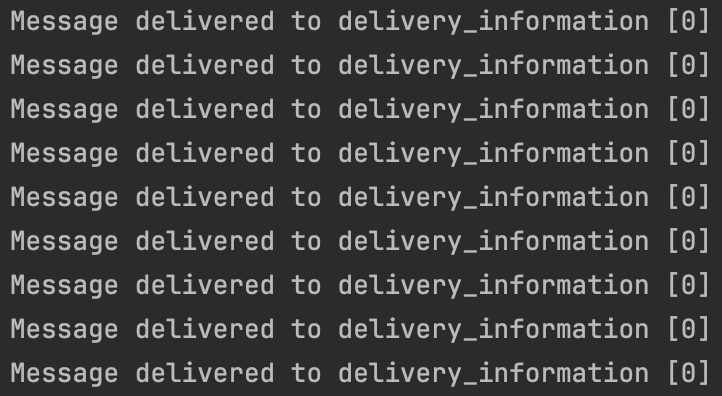
실행해보면 메시지가 publish 되어 delivery_report 함수에 지정한 메시지가 출력되는 것을 확인할 수 있다.
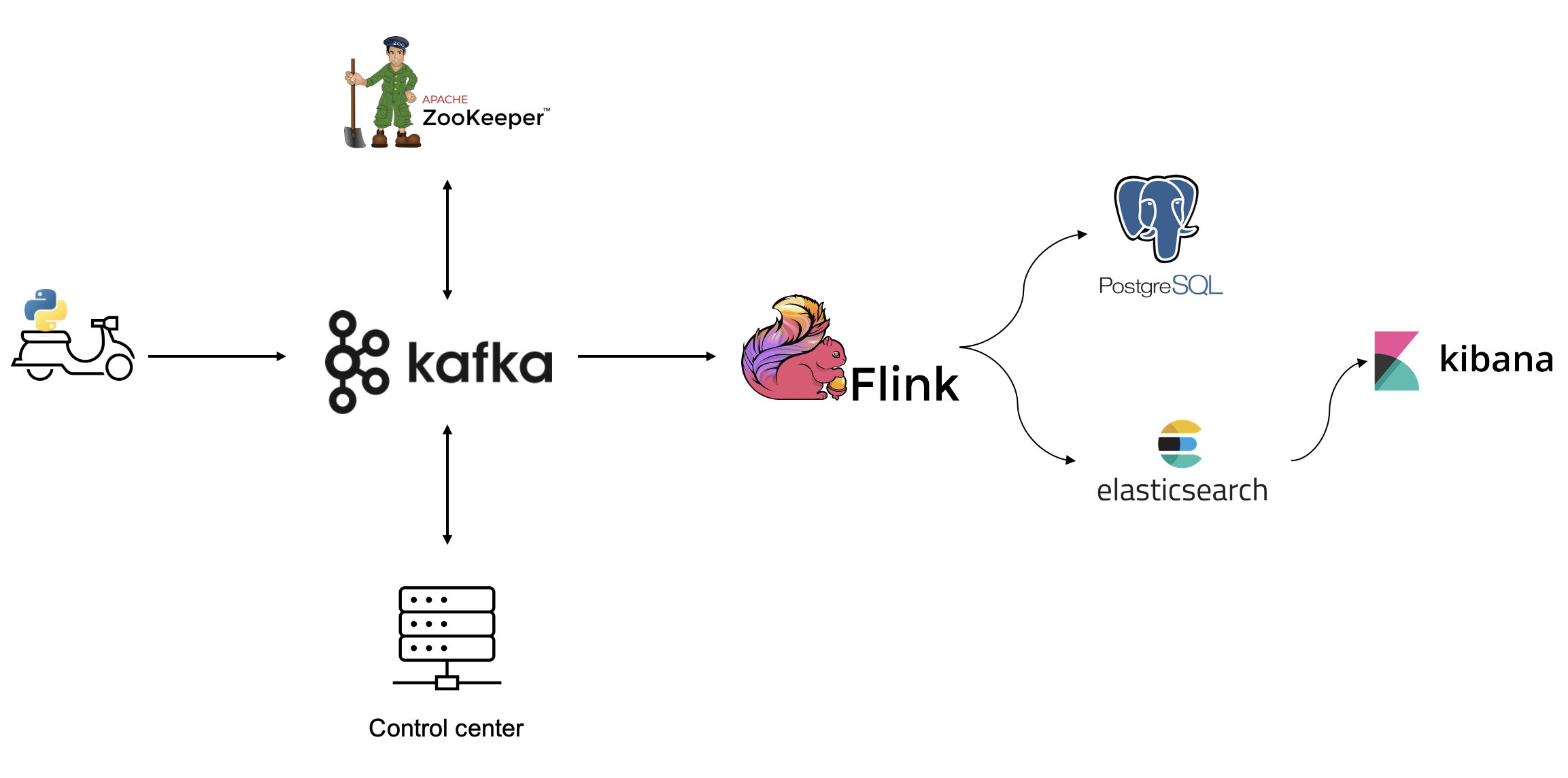
Control Center
실제 kafka에 메시지가 잘 publish 되는지 확인하기 위해 localhost:9021에 접속해본다.
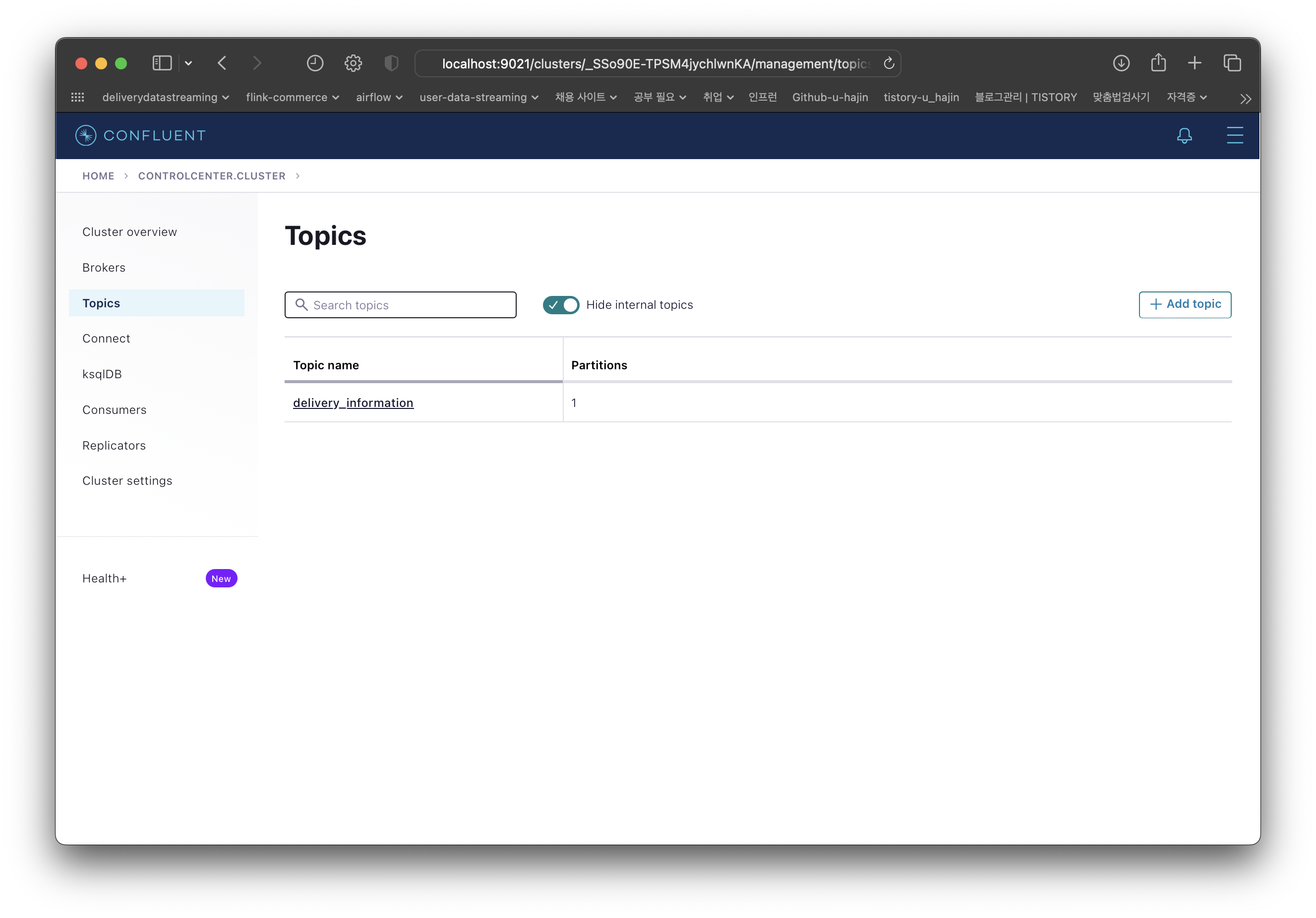
topic이 잘 생성된 것을 확인할 수 있다.

생성한 데이터가 잘 publish 되었다.
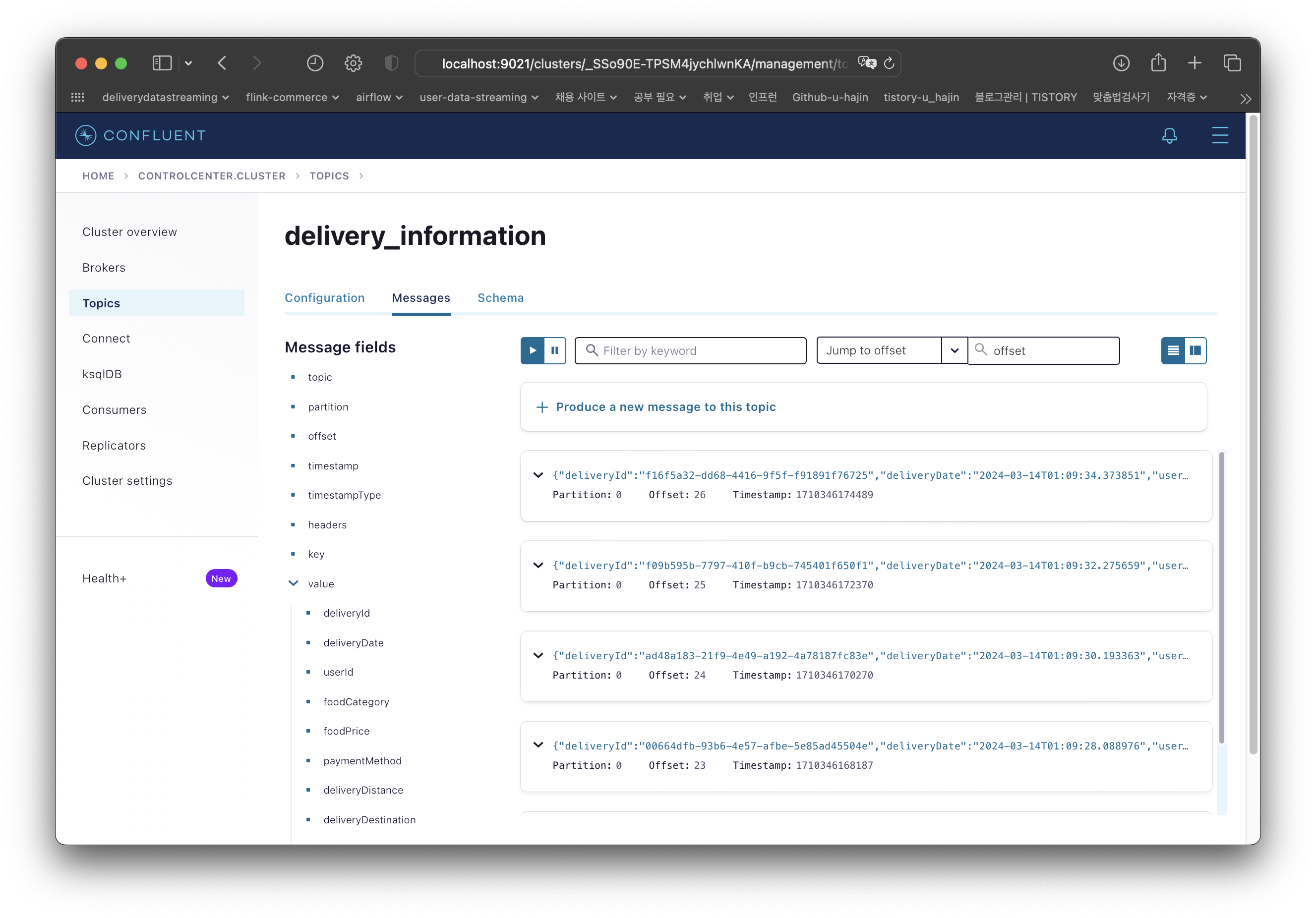
500초동안 1초 간격으로 데이터를 생성하고 계속해서 publish 하도록 설정해놨기 때문에 실시간으로 메시지가 차곡차곡 쌓인다.
Github
GitHub - u-hajin/delivery-data-streaming
Contribute to u-hajin/delivery-data-streaming development by creating an account on GitHub.
github.com
'Data > Project' 카테고리의 다른 글
| Project | 실시간 배달 주문 데이터 처리 - Flink Map, KeyBy, Reduce를 이용한 데이터 변환, 집계 처리 (2) | 2024.05.03 |
|---|---|
| Project | 실시간 배달 주문 데이터 처리 - PostgreSQL Table 생성 및 데이터 삽입 (0) | 2024.05.03 |
| Project | 실시간 배달 주문 데이터 처리 - Flink Job을 사용한 Kafka 스트리밍 (0) | 2024.03.27 |
| Project | 실시간 배달 주문 데이터 처리 - 환경 구축 (2) | 2024.03.18 |
| Project | 실시간 배달 주문 데이터 처리 - 시스템 구조 및 설명 (0) | 2024.03.18 |
데이터 구조
Json 형식으로 kafka에 메시지를 publish한다.
| key | value |
| deliveryId | uuid |
| deliveryDate | 배달 주문 날짜 |
| userId | 배달 주문 고객 id |
| foodCategory | 음식 카테고리 |
| foodPrice | 음식 총 가격 |
| paymentMethod | 결제 방식 |
| deliveryDistance | 배달 거리 |
| deliveryDestination | 배달 목적지 |
| destinationLat | 배달 목적지의 위도 |
| destinationLon | 배달 목적지의 경도 |
| deliveryCharge | 배달 요금 |
배달 목적지의 위도, 경도를 데이터에 포함하는 이유는 elasticsearch의 지도를 활용하기 위해서다. 배달 목적지에 따른 주문 빈도수를 지도로 한번에 나타내면 좋을 것 같아 위도, 경도를 저장하기로 했다.
데이터 생성
faker = Faker() KST = timezone(timedelta(hours=9)) def generate_delivery_data(): data = {'deliveryId': faker.uuid4(), 'deliveryDate': datetime.now(KST).strftime('%Y-%m-%dT%H:%M:%S.%f%z'), 'userId': faker.simple_profile()['username'], 'foodCategory': random.choice(['한식', '중식', '양식', '일식', '아시안', '치킨', '버거', '분식']), 'foodPrice': round(random.randint(5000, 12000) * random.randint(1, 4), -1), 'paymentMethod': random.choice(['현금', '신용/체크카드', '네이버페이', '카카오페이', '애플페이', '토스페이']), 'deliveryDistance': round(random.uniform(0.2, 3.0), 1), 'deliveryDestination': random.choice(seoul_addresses)} kakaoApiKey = config['AUTHORIZATION']['KakaoApiKey'] location = get_location(data['deliveryDestination'], kakaoApiKey)['documents'][0] data['destinationLat'] = location['y'] data['destinationLon'] = location['x'] data['deliveryCharge'] = round(random.randint(1000, 5000) + (data['deliveryDistance'] * 500), -1) return data
- deliveryId : faker 라이브러리를 사용해 uuid 값을 생성한다.
- deliveryDate : 타임존을 한국으로 설정해 현재 시간을 저장한다.
- userId : faker 라이브러리를 사용해 user 아이디를 생성한다.
- foodCategory : 총 8개의 카테고리 중 랜덤으로 하나의 값만 뽑는다.
- foodPrice : 5000~12000 범위를 갖는 랜덤 정수에 랜덤 값(1~4)을 곱해 음식 가격을 생성한다. 일의 자리는 무조건 0으로 지정한다.
- paymentMethod : 총 6개의 방식 중 랜덤으로 하나의 방식만 뽑는다.
- deliveryDistance : 0.2~3.0 범위를 갖는 랜덤 실수를 생성한다.
- deliveryDestination : seoul_addresses 리스트에 125개의 주소가 저장되어 있다. 그 중 하나의 값을 랜덤으로 뽑는다. 주소 형식은 '서울특별시 xx구 xx로'로 통일되어 있다.
- deliveryCharge : 1000~5000 범위를 갖는 랜덤 정수에 배달 거리에 따라 가중치를 주어 값을 생성한다. 일의 자리는 무조건 0으로 지정한다.
위도, 경도 추출
deliveryDestination key에 저장되어 있는 주소를 가지고 위도, 경도를 추출해야 한다. 여러 API 중 kakao에서 제공하는 API가 제일 적당해보였다.
def get_location(address, apiKey): url = 'https://dapi.kakao.com/v2/local/search/address.json?query=' + address headers = {'Authorization': apiKey} location = requests.get(url, headers=headers).json() return location
deliveryDestination 문자열을 입력하면 kakao API를 통해 위도, 경도를 추출할 수 있다. 직접 발급받은 kakao api key를 넘겨줘야 한다.
반환받은 location을 출력하면 아래와 같다.
'서울특별시 강서구 화곡로'를 입력하면 얻을 수 있는 값인데 '화곡로'가 포함된 모든 주소에 대한 정보가 포함되어 있다. 이 중 맨 처음 요소의 위도, 경도를 사용하기로 결정했다.
kakaoApiKey = config['AUTHORIZATION']['KakaoApiKey'] location = get_location(data['deliveryDestination'], kakaoApiKey)['documents'][0] data['destinationLat'] = location['y'] data['destinationLon'] = location['x']
kafka에 publish할 데이터이다.
Kafka 메시지 Produce, Publish
confluent_kafka 라이브러리를 사용할 것이다.
먼저 공식 문서를 확인해본다.
confluent_kafka API — confluent-kafka 2.3.0 documentation
Docs » confluent_kafka API View page source confluent_kafka API A reliable, performant and feature-rich Python client for Apache Kafka v0.8 and above. Guides Client API Serialization API Supporting classes ExperimentalThese classes are experimental and ar
docs.confluent.io
producer가 여러개이므로 읽어보고 어떤 클래스를 사용해야 할지 봤다. 메시지를 전송하기 전 직렬화가 필요하면 SerializingProducer를 사용하면 된다고 한다.
추후 버전에는 포함되지 않거나 달라질 수 있으니 주의해야 한다. Producer 클래스를 상속 받았다고 한다.
그럼 다시 Producer 페이지로 가서 어떻게 producer를 생성해야 하는지 봐야한다.
딕셔너리 형태로 bootstrap.servers를 명시하면 된다.
producer = SerializingProducer({ 'bootstrap.servers': config['KAFKA']['BootstrapServer'] }) # config['KAFKA']['BootstrapServer'] == 'localhost:9092,localhost:9093'
produce 함수의 파라미터 설명이다. topic, key, value, on_delivery만 넘겨주면 될 것 같다.
on_delivery에는 메시지 전달에 성공하거나 실패했을 때 poll(), flush()로부터 호출될 콜백 함수를 등록한다.
def delivery_report(error, msg): if error is not None: print(f'Message delivery failed: {error}') else: print(f'Message delivered to {msg.topic()} [{msg.partition()}]')
topic = config['KAFKA']['Topic'] def kafka_publish(producer, topic, data): producer.produce( topic=topic, key=data['deliveryId'], value=json.dumps(data, ensure_ascii=False), on_delivery=delivery_report ) producer.poll(0)
Topic 이름은 delivery_information이고 key 값은 생성한 데이터의 deliveryId로 지정했다.
produce 함수 호출로 메시지를 publish한다.
실행해보면 메시지가 publish 되어 delivery_report 함수에 지정한 메시지가 출력되는 것을 확인할 수 있다.
Control Center
실제 kafka에 메시지가 잘 publish 되는지 확인하기 위해 localhost:9021에 접속해본다.
topic이 잘 생성된 것을 확인할 수 있다.
생성한 데이터가 잘 publish 되었다.
500초동안 1초 간격으로 데이터를 생성하고 계속해서 publish 하도록 설정해놨기 때문에 실시간으로 메시지가 차곡차곡 쌓인다.
Github
GitHub - u-hajin/delivery-data-streaming
Contribute to u-hajin/delivery-data-streaming development by creating an account on GitHub.
github.com
'Data > Project' 카테고리의 다른 글
| Project | 실시간 배달 주문 데이터 처리 - Flink Map, KeyBy, Reduce를 이용한 데이터 변환, 집계 처리 (2) | 2024.05.03 |
|---|---|
| Project | 실시간 배달 주문 데이터 처리 - PostgreSQL Table 생성 및 데이터 삽입 (0) | 2024.05.03 |
| Project | 실시간 배달 주문 데이터 처리 - Flink Job을 사용한 Kafka 스트리밍 (0) | 2024.03.27 |
| Project | 실시간 배달 주문 데이터 처리 - 환경 구축 (2) | 2024.03.18 |
| Project | 실시간 배달 주문 데이터 처리 - 시스템 구조 및 설명 (0) | 2024.03.18 |